Go 语言学习:基础语法
Go 基础
简介
Go 语言主要特征
- 自动立即回收。
- 更丰富的内置类型。
- 函数多返回值。
- 错误处理。
- 匿名函数和闭包。
- 类型和接口。
- 并发编程。
- 反射。
- 语言交互性。
25个关键字
1
2
3
4
5
go break switch case select
package import func if else
const type interface struct map
range chan defer default for
return goto continue fallthrough var
37个保留字
1
2
3
4
5
6
7
Constants: nil true false iota
Types: byte rune bool string error
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
complex64 complex128 float32 float64
Funcs: append delete cap len make new close
panic recover copy complex real imag
可见性
- 声明在函数内部,仅函数内可见。
- 声明在函数外部,当前包内可见。
- 声明在函数外部,并且首字母大写,所有包都可见。
内置类型
值类型
1
2
3
4
5
6
7
bool
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64
float32 float64
complex64 complex128
array
string
引用类型
1
slice chan map
内置函数
1
2
3
4
5
6
7
8
9
10
11
12
13
append -- 用来追加元素到数组、slice中,返回修改后的数组、slice
close -- 主要用来关闭channel
delete -- 从map中删除key对应的value
panic -- 停止常规的goroutine (panic和recover:用来做错误处理)
recover -- 允许程序定义goroutine的panic动作
imag -- 返回complex的实部 (complex、real imag:用于创建和操作复数)
real -- 返回complex的虚部
make -- 用来分配内存,返回Type本身(只能应用于slice, map, channel)
new -- 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
cap -- capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
copy -- 用于复制和连接slice,返回复制的数目
len -- 来求长度,比如string、array、slice、map、channel ,返回长度
print、println -- 底层打印函数,在部署环境中建议使用 fmt 包
内置接口
1
2
3
type error interface {
Error() string
}
init函数和main函数
init函数
Go语言中init函数用于包的初始化,有着以下特征:
- init函数是用于程序执行前做包的初始化的函数,比如初始化包里的变量等
- 每个包可以拥有多个init函数
- 包的每个源文件也可以拥有多个init函数
- 同一个包中多个init函数的执行顺序go语言没有明确的定义(说明)
- 不同包的init函数按照包导入的依赖关系决定该初始化函数的执行顺序
- init函数不能被其他函数调用,而是在main函数执行之前,自动被调用
mian函数
main函数是Go语言程序的默认入口函数(主函数)。
1
2
3
func main(){
//函数体
}
init函数与main函数的异同
相同点:
- 两个函数在定义时不能有任何的参数和返回值,且Go程序自动调用。
不同点:
- init可以应用于任意包中,且可以重复定义多个。
- main函数只能定义在main包中,且只能定义一个。
下划线
_是特殊标识符,用于忽略结果,它有以下两个作用:
- 在
import包时使用,可以调用包的init函数,但不导入包。 - 将函数返回值赋值给
_,表示忽略此变量,如果用变量的话,不使用,编译器是会报错的。
变量与常量
Go语言中的变量需要声明后才能使用,同一作用域内不支持重复声明。并且Go语言的变量声明后必须使用。
声明变量的几种方式
标准声明
1
var 变量名 变量类型
批量声明
1
2
3
4
5
var {
a string
b int
c bool
}
变量初始化
Go语言在声明变量的时候,会自动对变量对应的内存区域进行初始化操作。每个变量会被初始化成其类型的默认值,例如: 整型和浮点型变量的默认值为0。 字符串变量的默认值为空字符串。 布尔型变量默认为false。 切片、函数、指针变量的默认为nil。
标准初始化
1
var a string = "hello world"
一次初始化多个变量
1
2
// 编译器会根据等号右边的值来推导变量的类型完成初始化
var a,b = "hello","world"
在函数内部,可以使用更简略的 := 方式声明并初始化变量。
1
2
3
4
5
6
7
8
9
10
package main
import "fmt"
var m = 100
func main() {
a := 5
fmt.Println(a,m)
}
匿名变量 _ ,匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。
1
2
3
4
5
6
7
8
9
func foo() (int, string) {
return 10, "Q1mi"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}
常量
相对于变量,常量是恒定不变的值,多用于定义程序运行期间不会改变的那些值。 常量的声明和变量声明非常类似,只是把var换成了const,常量在定义的时候必须赋值。
标准声明
1
2
const pi = 3.1415
const e = 2.7182
批量声明
1
2
3
4
const {
pi = 3.1415
e = 2.7182
}
const同时声明多个常量时,如果省略了值则表示和上面一行的值相同。
1
2
3
4
5
const (
n1 = 100
n2
n3
)
iota
iota是go语言的常量计数器,只能在常量的表达式中使用。 iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
标准例子
1
2
3
4
5
6
const (
n1 = iota //0
n2 //1
n3 //2
n4 //3
)
使用_跳过某些值
1
2
3
4
5
6
const (
n1 = iota //0
n2 //1
_
n4 //3
)
iota声明中间插队
1
2
3
4
5
6
7
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2
n4 //3
)
const n5 = iota //0
定义数量级
1
2
3
4
5
6
7
8
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
多个iota定义在一行
1
2
3
4
5
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3
e, f //3,4
)
基本类型
整型
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64对应的无符号整型:uint8、uint16、uint32、uint64。其中,uint8就是我们熟知的byte型,int16对应C语言中的short型,int64对应C语言中的long型。
浮点型
Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准: float32 的浮点数的最大范围约为3.4e38,可以使用常量定义:math.MaxFloat32。 float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
复数
complex64和complex128 复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
布尔值
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
注意:
- 布尔类型变量的默认值为false。
- Go 语言中不允许将整型强制转换为布尔型.
- 布尔型无法参与数值运算,也无法与其他类型进行转换。
字符串
Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。 Go 语言里的字符串的内部实现使用UTF-8编码。 字符串的值为双引号(“)中的内容,可以在Go语言的源码中直接添加非ASCII码字符。
多行字符串,反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
1
2
3
4
5
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.Contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
byte和rune类型
组成每个字符串的元素叫做“字符”,Go 语言的字符有以下两种:
- uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。
- rune类型,代表一个 UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。 Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾
1
2
3
4
5
6
7
8
9
10
11
12
// 遍历字符串
func traversalString() {
s := "pprof.cn博客"
for i := 0; i < len(s); i++ { //byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}
输出:
1
2
112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 229(å) 141() 154() 229(å) 174(®) 162(¢)
112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 21338(博) 23458(客)
因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的 字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
强制类型转换的基本语法如下:
1
T(表达式)
数组Array
数组是同一种数据类型的固定长度的序列。数组是值类型,赋值和传参会复制整个数组,而不是指针。因此会改变副本的值,不会改变本身的值。
一维数组初始化
1
2
3
4
var arr0 [5]int = [5]int {1,2,3,4,5}
var arr1 [3]int = [3]int{1,2} //未初始化的元素默认值为0。
var arr2 = [...]int{1,2} //通过初始化值确定数组长度。
var arr3 = [5]int{2:1,3:2} //使用索引号初始化元素。
获取数组长度
1
2
a := [...]int[1,2]
println(len(a),cap(a))
切片Slice
切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。切片的长度可以改变,因此,切片是一个可变的数组。
创建切片的几种方式
1
2
3
4
5
6
7
8
9
10
11
// 声明切片
var s1 []int
// :=
s2 := []int{}
// make([]type, len)
s3 := make([]int,0)
// make([]type, len, cap)
s4 := make([]int,0,0)
// 从数组切片
arr := [...]int{1,2,3,4,5,6}
s5 := arr[1:3] //前包后不包
切片的内部布局
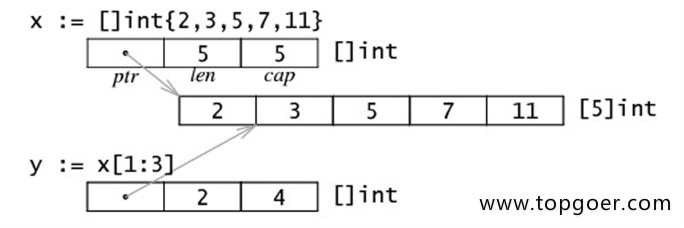
切片读写操作的实际目标是底层数组,对底层数组元素进行修改,相关的切片元素都会同步变动。
1
2
3
4
5
6
7
8
9
10
11
func TestSlice(t *testing.T) {
var arr = [...]int{1, 2, 3, 4, 5, 6}
s1 := arr[:2]
s2 := arr[:4]
arr[0] = 9
s1 = append(s1, 8, 7)
fmt.Printf("arr: %v\n", arr)
fmt.Printf("s1: %v\n", s1)
fmt.Printf("s2: %v\n", s2)
}
输出:
1
2
3
arr: [9 2 8 7 5 6]
s1: [9 2 8 7]
s2: [9 2 8 7]
但是当slice内元素超出slice.cap限制时,就会重新分配底层数组,即便原数组并未填满。
1
2
3
4
5
6
7
8
9
10
11
12
func TestSlice(t *testing.T) {
var arr = [...]int{1, 2, 3, 4, 5, 6}
s1 := arr[:2:3]
s2 := arr[:4]
arr[0] = 9
s1 = append(s1, 8, 7)
fmt.Printf("arr: %v\n", arr)
fmt.Printf("s1: %v\n", s1)
fmt.Printf("s2: %v\n", s2)
}
输出:
1
2
3
arr: [9 2 3 4 5 6]
s1: [9 2 8 7]
s2: [9 2 3 4]
切片拷贝:函数 copy 在两个 slice 间复制数据,复制长度以 len 小的为准。两个 slice 可指向同一底层数组,允许元素区间重叠。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
fmt.Println("array data : ", data)
s1 := data[8:]
s2 := data[:5]
fmt.Printf("slice s1 : %v\n", s1)
fmt.Printf("slice s2 : %v\n", s2)
copy(s2, s1)
fmt.Printf("copied slice s1 : %v\n", s1)
fmt.Printf("copied slice s2 : %v\n", s2)
fmt.Println("last array data : ", data)
}
输出:
1
2
3
4
5
6
array data : [0 1 2 3 4 5 6 7 8 9]
slice s1 : [8 9]
slice s2 : [0 1 2 3 4]
copied slice s1 : [8 9]
copied slice s2 : [8 9 2 3 4]
last array data : [8 9 2 3 4 5 6 7 8 9]
cap重新分配规律
append 后的 slice,如何超出了cap限制,就会重新分配底层数组,并复制数据,通常以 2 倍容量重新分配底层数组。在大批量添加数据时,建议一次性分配足够大的空间,以减少内存分配和数据复制开销。或初始化足够长的 len 属性,改用索引号进行操作。及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
指针
区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针。
取地址与取值
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用&字符放在变量前面对变量进行“取地址”操作。*根据地址取出地址指向的值。
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
- 当一个指针被定义后没有分配到任何变量时,它的值为 nil。
1
2
3
4
5
6
7
8
func TestPtr(t *testing.T) {
a := 10
b := &a
fmt.Printf("a:%d ptr:%p\n", a, &a)
fmt.Printf("b:%p type:%T\n", b, b)
fmt.Println(&b)
fmt.Printf("*b: %v\n", *b)
}
输出:
1
2
3
4
a:10 ptr:0xc00000a2a0
b:0xc00000a2a0 type:*int
0xc00005e050
*b: 10
new
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。
1
2
3
4
5
6
7
8
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
Map
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
基本使用
初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func TestMap(t *testing.T) {
// make(map[KeyType]ValueType, [cap]) 其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
scoreMap := make(map[string]int,8)
scoreMap["jason"] = 5
scoreMap["lilei"] = 6
fmt.Printf("scoreMap: %v\n", scoreMap)
fmt.Printf("scoreMap[\"jason\"]: %v\n", scoreMap["jason"])
//map也支持在声明的时候填充元素
scoreMap1 := map[string]int{
"jason": 5,
"mike": 7,
}
fmt.Printf("scoreMap1: %v\n", scoreMap1)
}
判断某个键是否存在
1
2
3
4
5
scoreMap := make(map[string]int,8)
scoreMap["jason"] = 5
if val,ok := scoreMap["jason"];ok {
fmt.Println(val)
}
遍历,遍历map时的元素顺序与添加键值对的顺序无关。
1
2
3
4
5
6
7
8
9
10
11
12
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["王五"] = 60
for k,v := range scoreMap {
fmt.Println(k,v)
}
//只遍历key
for k := range scoreMap {
fmt.Println(k)
}
删除键值对
1
2
3
4
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
delete(scoreMap,"张三")
自定义类型与类型别名
自定义类型
Go语言中可以使用type关键字来定义自定义类型。自定义类型是定义了一个全新的类型。
1
type myInt int32
类型别名
类型别名规定:myInt只是int32的别名,本质上myInt与int32是同一个类型。
1
type myInt = int32
我们之前见过的rune和byte就是类型别名,他们的定义如下:
1
2
type byte = uint8
type rune = int32
类型定义和类型别名的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
//类型定义
type NewInt int
//类型别名
type MyInt = int
func main() {
var a NewInt
var b MyInt
fmt.Printf("type of a:%T\n", a) //type of a:main.NewInt
fmt.Printf("type of b:%T\n", b) //type of b:int
}
结果显示a的类型是main.NewInt,表示main包下定义的NewInt类型。b的类型是int。MyInt类型只会在代码中存在,编译完成时并不会有MyInt类型。
结构体
Go语言中的基础数据类型可以表示一些事物的基本属性,但是当我们想表达一个事物的全部或部分属性时,这时候再用单一的基本数据类型明显就无法满足需求了,Go语言提供了一种自定义数据类型,可以封装多个基本数据类型,这种数据类型叫结构体,英文名称struct。 也就是我们可以通过struct来定义自己的类型了。
定义
1
2
3
4
5
type person struct {
name string
city string
age int8
}
实例化
1
2
3
4
5
var p1 person
p1.name = "pprof.cn"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) //p1={pprof.cn 北京 18}
匿名结构体
1
2
3
4
var user struct{Name string; Age int}
user.Name = "pprof.cn"
user.Age = 18
fmt.Printf("%#v\n", user)
创建指针类型结构体
1
2
3
4
5
var p2 = new(person)
p2.name = "测试"
p2.age = 18
p2.city = "北京"
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"测试", city:"北京", age:18}
取结构体的地址实例化
1
2
3
4
5
6
7
p3 := &person{}
fmt.Printf("%T\n", p3) //*main.person
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"", city:"", age:0}
p3.name = "博客"
p3.age = 30
p3.city = "成都"
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"博客", city:"成都", age:30}
结构体初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
p5 := person{
name: "pprof.cn",
city: "北京",
age: 18,
}
p6 := &person{
name: "pprof.cn",
city: "北京",
age: 18,
}
//当某些字段没有初始值的时候,该字段可以不写。此时,没有指定初始值的字段的值就是该字段类型的零值。
p7 := &person{
city: "北京",
}
/*1.必须初始化结构体的所有字段。
2.初始值的填充顺序必须与字段在结构体中的声明顺序一致。
3.该方式不能和键值初始化方式混用。*/
p8 := &person{
"pprof.cn",
"北京",
18,
}
构造函数
Go语言的结构体没有构造函数,我们可以自己实现。 例如,下方的代码就实现了一个person的构造函数。 因为struct是值类型,如果结构体比较复杂的话,值拷贝性能开销会比较大,所以该构造函数返回的是结构体指针类型。
1
2
3
4
5
6
7
func newPerson(name, city string, age int8) *person {
return &person{
name: name,
city: city,
age: age,
}
}
方法和接收者
Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。接收者的概念就类似于其他语言中的this或者 self。
方法的定义格式如下:
1
2
3
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
函数体
}
其中:
- 接收者变量:接收者中的参数变量名在命名时,官方建议使用接收者类型名的第一个小写字母,而不是self、this之类的命名。例如,Person类型的接收者变量应该命名为 p,Connector类型的接收者变量应该命名为c等。
- 接收者类型:接收者类型和参数类似,可以是指针类型和非指针类型。
- 方法名、参数列表、返回参数:具体格式与函数定义相同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//Person 结构体
type Person struct {
name string
age int8
}
//NewPerson 构造函数
func NewPerson(name string, age int8) *Person {
return &Person{
name: name,
age: age,
}
}
//Dream Person做梦的方法
func (p Person) Dream() {
fmt.Printf("%s的梦想是学好Go语言!\n", p.name)
}
func main() {
p1 := NewPerson("测试", 25)
p1.Dream()
}
方法与函数的区别是,函数不属于任何类型,方法属于特定的类型。
指针类型的接收者
指针类型的接收者由一个结构体的指针组成,由于指针的特性,调用方法时修改接收者指针的任意成员变量,在方法结束后,修改都是有效的。这种方式就十分接近于其他语言中面向对象中的this或者self。 例如我们为Person添加一个SetAge方法,来修改实例变量的年龄。
1
2
3
4
5
6
7
8
9
10
func (p *Person) SetAge(newAge int8) {
p.age = newAge
}
func main() {
p1 := NewPerson("测试", 25)
fmt.Println(p1.age) // 25
p1.SetAge(30)
fmt.Println(p1.age) // 30
}
值类型的接收者
当方法作用于值类型接收者时,Go语言会在代码运行时将接收者的值复制一份。在值类型接收者的方法中可以获取接收者的成员值,但修改操作只是针对副本,无法修改接收者变量本身。
1
2
3
4
5
6
7
8
9
10
11
func (p Person) SetAge2(newAge int8) {
p.age = newAge
}
func main() {
p1 := NewPerson("测试", 25)
p1.Dream()
fmt.Println(p1.age) // 25
p1.SetAge2(30) // (*p1).SetAge2(30)
fmt.Println(p1.age) // 25
}
什么时候应该使用指针类型接收者
- 需要修改接收者中的值
- 接收者是拷贝代价比较大的大对象
- 保证一致性,如果有某个方法使用了指针接收者,那么其他的方法也应该使用指针接收者。
任意类型添加方法
在Go语言中,接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。 举个例子,我们基于内置的int类型使用type关键字可以定义新的自定义类型,然后为我们的自定义类型添加方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
//MyInt 将int定义为自定义MyInt类型
type MyInt int
//SayHello 为MyInt添加一个SayHello的方法
func (m MyInt) SayHello() {
fmt.Println("Hello, 我是一个int。")
}
func main() {
var m1 MyInt
m1.SayHello() //Hello, 我是一个int。
m1 = 100
fmt.Printf("%#v %T\n", m1, m1) //100 main.MyInt
}
注意事项: 非本地类型不能定义方法,也就是说我们不能给别的包的类型定义方法。
结构体的匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//Person 结构体Person类型
type Person struct {
string
int
}
func main() {
p1 := Person{
"pprof.cn",
18,
}
fmt.Printf("%#v\n", p1) //main.Person{string:"pprof.cn", int:18}
fmt.Println(p1.string, p1.int) //pprof.cn 18
}
匿名字段默认采用类型名作为字段名,结构体要求字段名称必须唯一,因此一个结构体中同种类型的匿名字段只能有一个。
嵌套结构体
一个结构体中可以嵌套包含另一个结构体或结构体指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//Address 地址结构体
type Address struct {
Province string
City string
}
//User 用户结构体
type User struct {
Name string
Gender string
Address Address
}
func main() {
user1 := User{
Name: "pprof",
Gender: "女",
Address: Address{
Province: "黑龙江",
City: "哈尔滨",
},
}
fmt.Printf("user1=%#v\n", user1)//user1=main.User{Name:"pprof", Gender:"女", Address:main.Address{Province:"黑龙江", City:"哈尔滨"}}
}
嵌套匿名结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//Address 地址结构体
type Address struct {
Province string
City string
}
//User 用户结构体
type User struct {
Name string
Gender string
Address //匿名结构体
}
func main() {
var user2 User
user2.Name = "pprof"
user2.Gender = "女"
user2.Address.Province = "黑龙江" //通过匿名结构体.字段名访问
user2.City = "哈尔滨" //直接访问匿名结构体的字段名
fmt.Printf("user2=%#v\n", user2) //user2=main.User{Name:"pprof", Gender:"女", Address:main.Address{Province:"黑龙江", City:"哈尔滨"}}
}
当访问结构体成员时会先在结构体中查找该字段,找不到再去匿名结构体中查找。
嵌套结构体的字段名冲突
嵌套结构体内部可能存在相同的字段名。这个时候为了避免歧义需要指定具体的内嵌结构体的字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
//Address 地址结构体
type Address struct {
Province string
City string
CreateTime string
}
//Email 邮箱结构体
type Email struct {
Account string
CreateTime string
}
//User 用户结构体
type User struct {
Name string
Gender string
Address
Email
}
func main() {
var user3 User
user3.Name = "pprof"
user3.Gender = "女"
// user3.CreateTime = "2019" //ambiguous selector user3.CreateTime
user3.Address.CreateTime = "2000" //指定Address结构体中的CreateTime
user3.Email.CreateTime = "2000" //指定Email结构体中的CreateTime
}
结构体的“继承”
Go语言中使用结构体也可以实现其他编程语言中面向对象的继承。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
//Animal 动物
type Animal struct {
name string
}
func (a *Animal) move() {
fmt.Printf("%s会动!\n", a.name)
}
//Dog 狗
type Dog struct {
Feet int8
*Animal //通过嵌套匿名结构体实现继承
}
func (d *Dog) wang() {
fmt.Printf("%s会汪汪汪~\n", d.name)
}
func main() {
d1 := &Dog{
Feet: 4,
Animal: &Animal{ //注意嵌套的是结构体指针
name: "乐乐",
},
}
d1.wang() //乐乐会汪汪汪~
d1.move() //乐乐会动!
}
结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问)。
结构体标签(Tag)
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。
Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
1
`key1:"value1" key2:"value2"`
结构体标签由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。键值对之间使用一个空格分隔。 注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
例如我们为Student结构体的每个字段定义json序列化时使用的Tag:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//Student 学生
type Student struct {
ID int `json:"id"` //通过指定tag实现json序列化该字段时的key
Gender string //json序列化是默认使用字段名作为key
name string //私有不能被json包访问
}
func main() {
s1 := Student{
ID: 1,
Gender: "女",
name: "pprof",
}
data, err := json.Marshal(s1)
if err != nil {
fmt.Println("json marshal failed!")
return
}
fmt.Printf("json str:%s\n", data) //json str:{"id":1,"Gender":"女"}
}